DD-PPO: Learning Near-Perfect PointGoal Navigators from 2.5 Billion Frames
Abstract
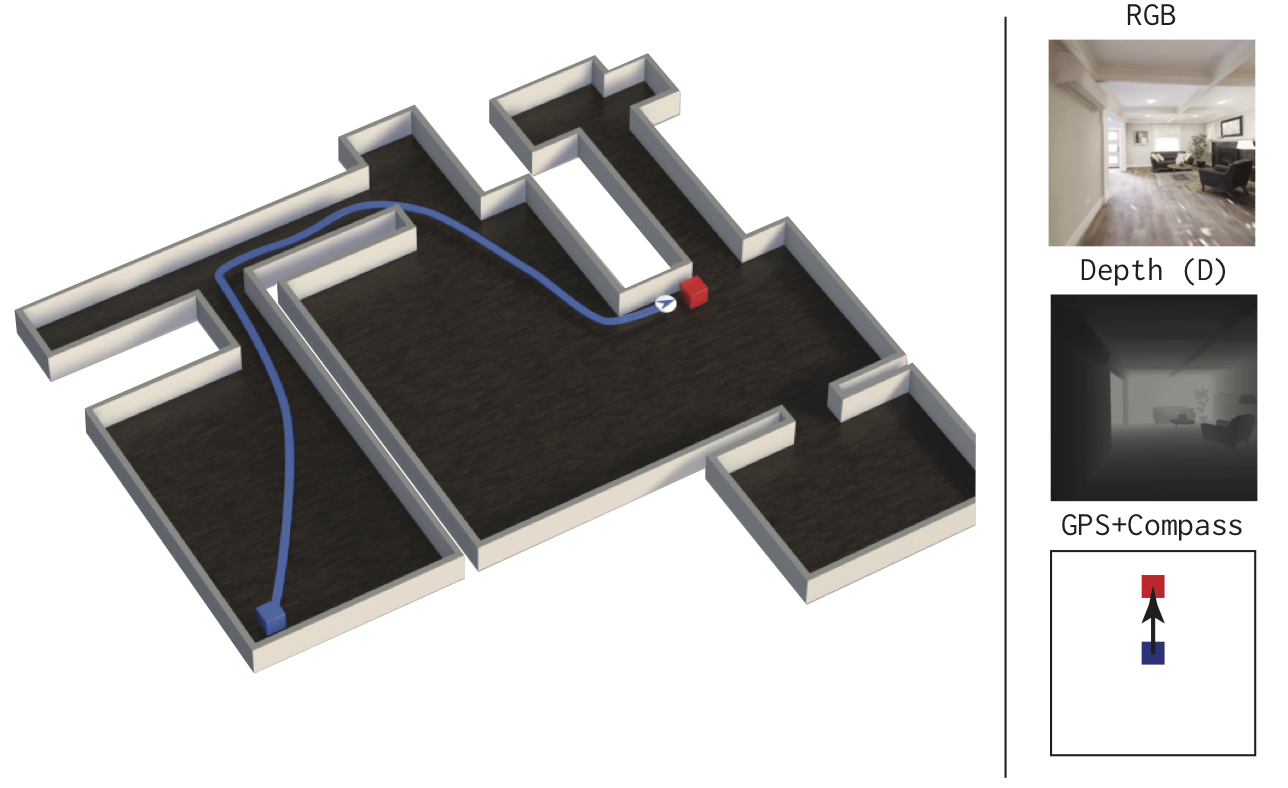
We present Decentralized Distributed Proximal Policy Optimization (DD-PPO), a method for distributed reinforcement learning in resource-intensive simulated environments. DD-PPO is distributed (uses multiple machines), decentralized (lacks a centralized server), and synchronous (no computation is ever ‘stale’), making it conceptually simple and easy to implement. In our experiments on training virtual robots to navigate in Habitat-Sim, DD-PPO exhibits near-linear scaling – achieving a speedup of 107x on 128 GPUs over a serial implementation. We leverage this scaling to train an agent for 2.5 Billion steps of experience (the equivalent of 80 years of human experience) – over 6 months of GPU-time training in under 3 days of wall-clock time with 64 GPUs.
This massive-scale training not only sets the state of art on Habitat Autonomous Navigation Challenge 2019, but essentially ‘solves’ the task – near-perfect autonomous navigation in an unseen environment without access to a map, directly from an RGB-D camera and a GPS+Compass sensor. Fortuitously, error vs computation exhibits a power-law-like distribution; thus, 90% of peak performance is obtained relatively early (at 100 million steps) and relatively cheaply (under 1 day with 8 GPUs). Finally, we show that the scene understanding and navigation policies learned can be transferred to other navigation tasks – the analog of ‘ImageNet pre-training + task-specific fine-tuning’ for embodied AI. Our model outperforms ImageNet pre-trained CNNs on these transfer tasks and can serve as a universal resource (all models + code will be publicly available).
Introduction
We present Decentralized Distributed PPO (DD-PPO). DD-PPO is synchronous and simple to implement. We leverage DD-PPO to achieve state of art results on the Habitat Autonomous Navigation Challenge 2019 and “solve” the task of PointGoal Navigation for agents with RGB-D and GPS+Compass sensors.
Specifically, these agents almost always reach the goal (failing on 1⁄1000 val episodes on average), and reach it nearly as efficiently as possible – nearly matching (within 3% of) the performance of a shortest-path oracle! It is worth stressing how uncompromising that comparison is – in a new environment, an agent navigating without a map traverses a path nearly matching the shortest path on the map. This means there is no scope for mistakes of any kind – no wrong turn at a crossroad, no back-tracking from a dead-end, no exploration or deviation of any kind from the shortest-path. Our hypothesis is that the model learns to exploit the statistical regularities in the floor-plans of indoor environments (apartments, offices) in our datasets.
Example Navigation Episodes
This video shows the agent successfully navigating 22 meters across a house (the top down map is shown for visualization purposes only). Notice the second right-hand turn the agent makes. While walking through the kitchen, the agent is able to infer that given the distance it still needs to travel, the goal cannot be directly forward, and it is not likely to be toward the left given that there is a wall. Thus it correctly decides to go right and begins to turn such that it rounds the corner perfectly.
This demonstrates the agents ability to expertly backtrack once it is clear that it made the wrong decision.
ICLR 2020 Presentation
The presentation of this work for ICLR 2020 can be found here iclr.cc/virtual_2020/poster_H1gX8C4YPr