Seeing the Un-Scene: Learning Amodal Semantic Maps for Room Navigation
Abstract
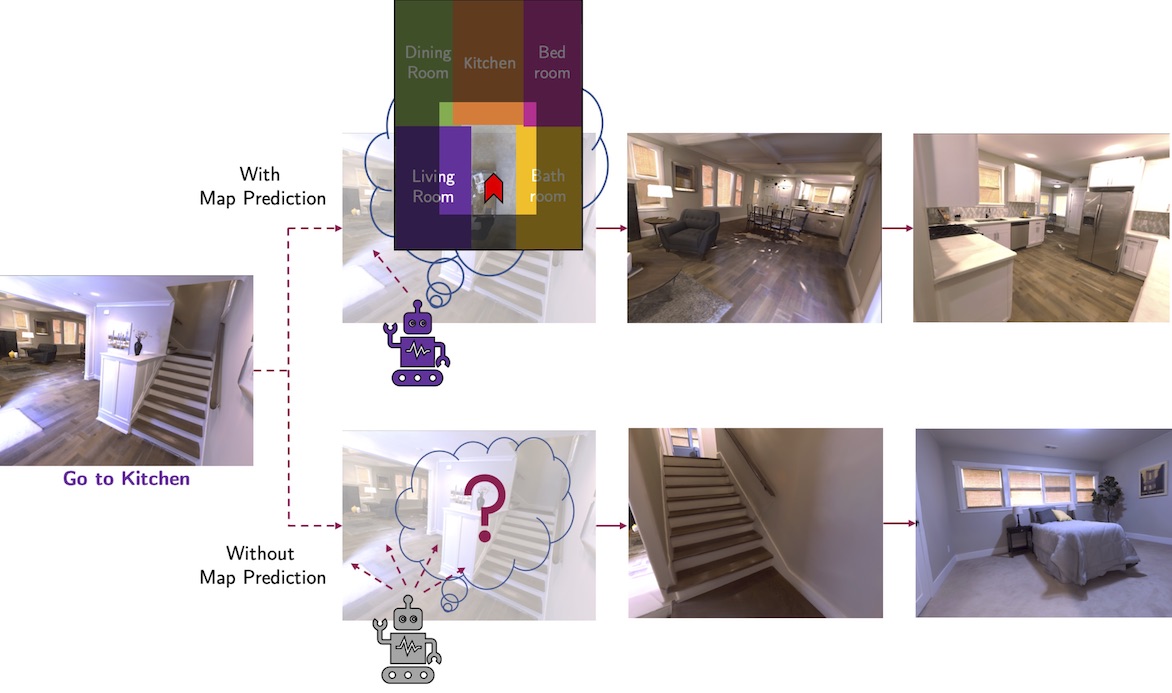
We introduce a learning-based approach for room navigation using semantic maps. Our proposed architecture learns to predict top-down belief maps of regions that lie beyond the agent’s field of view while modeling architectural and stylistic regularities in houses. First, we train a model to generate amodal semantic top-down maps indicating beliefs of location, size, and shape of rooms by learning the underlying architectural patterns in houses. Next, we use these maps to predict a point that lies in the target room and train a policy to navigate to the point. We empirically demonstrate that by predicting semantic maps, the model learns common correlations found in houses and generalizes to novel environments. We also demonstrate that reducing the task of room navigation to point navigation improves the performance further. We will make our code publicly available and hope our work paves the way for further research in this space.