THDA: Treasure Hunt Data Augmentation for Semantic Navigation
Abstract
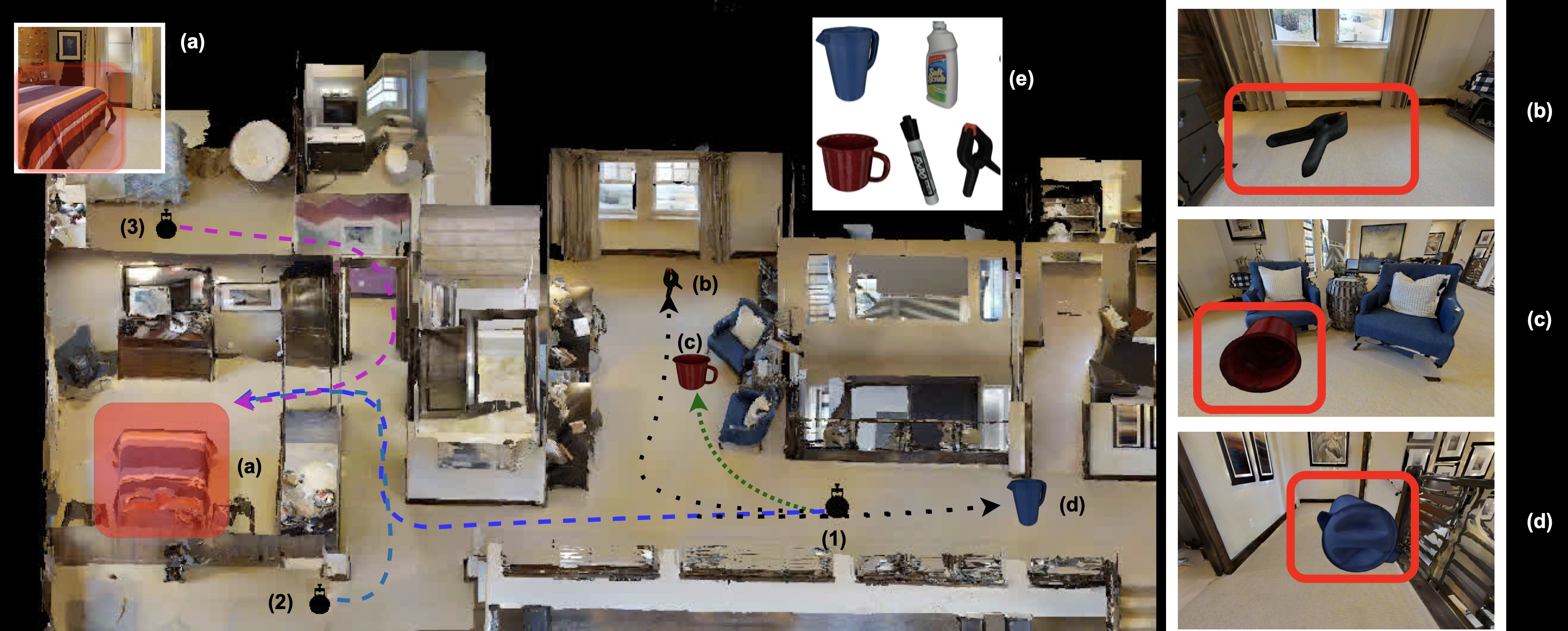
Can general-purpose neural models learn to navigate? For PointGoal navigation (‘go to ∆x, ∆y’), the answer is a clear ‘yes’ – mapless neural models composed of task- agnostic components (CNNs and RNNs) trained with large- scale model-free reinforcement learning achieve near-perfect performance. However, for ObjectGoal navigation (‘find a TV’), this is an open question; one we tackle in this paper. The current best-known result on ObjectNav with general-purpose models is 6% success rate. First, we show that the key problem is overfitting. Large-scale training results in 94% success rate on training environments and only 8% in validation. We observe that this stems from agents memorizing environment layouts during training – sidestepping the need for exploration and directly learning shortest paths to nearby goal objects. We show that this is a natural consequence of optimizing for the task metric (which in fact penalizes exploration), is enabled by powerful observation encoders, and is possible due to the finite set of training environment configurations Informed by our findings, we introduce Treasure Hunt Data Augmentation (THDA) to address overfitting in ObjectNav. THDA inserts 3D scans of household objects at arbitrary scene locations and uses them as ObjectNav goals – augmenting and greatly expanding the set of training layouts. Taken together with our other proposed changes, we improve the state of art on the Habitat ObjectGoal Navigation benchmark by 90% (from 14% success rate to 27%) and path efficiency by 48% (from 7.5 SPL to 11.1 SPL).