VER: Scaling On-Policy RL Leads to Emergence of Navigation in Embodied Rearrangement
Abstract
We present Variable Experience Rollout (VER), a technique for efficiently scaling batched on-policy reinforcement learning in heterogenous environments (where different environments take vastly different times for generating rollouts) to many GPUs residing on, potentially, many machines. VER combines the strengths of and blurs the line between synchronous and asynchronous on-policy RL methods (SyncOnRL and AsyncOnRL, respectively). Specifically, it learns from on-policy experience (like SyncOnRL) and has no synchronization points (like AsyncOnRL), enabling high throughput. We find that VER leads to significant and consistent speed-ups across a broad range of embodied navigation and mobile manipulation tasks in photorealistic 3D simulation environments. Specifically, for PointGoal navigation and ObjectGoal navigation in Habitat 1.0, VER is 60-100% faster (1.6-2x speedup) than DD-PPO, the current state of art for distributed SyncOnRL, with similar sample efficiency. For mobile manipulation tasks (open fridge/cabinet, pick/place objects) in Habitat 2.0 VER is 150% faster (2.5x speedup) on 1 GPU and 170% faster (2.7x speedup) on 8 GPUs than DD-PPO. Compared to SampleFactory (the current state-of-the-art AsyncOnRL), VER matches its speed on 1 GPU, and is 70% faster (1.7x speedup) on 8 GPUs with better sample efficiency. We leverage these speed-ups to train chained skills for GeometricGoal rearrangement tasks in the Home Assistant Benchmark (HAB). We find a surprising emergence of navigation in skills that do not ostensible require any navigation. Specifically, the Pick skill involves a robot picking an object from a table. During training the robot was always spawned close to the table and never needed to navigate. However, we find that if base movement is part of the action space, the robot learns to navigate then pick an object in new environments with 50% success, demonstrating surprisingly high out-of-distribution generalization.
Introduction
How can we combine the benefit of synchronous (high sample efficiency) and asynchronous (high throughput) systems for batched on-policy reinforcement learning?
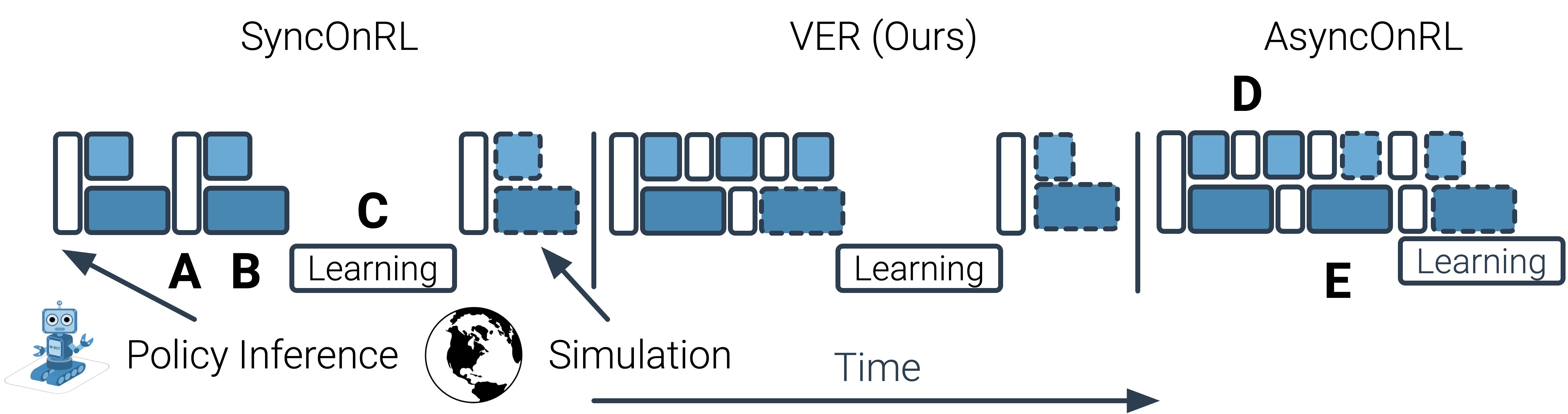
Systems for batched on-policy reinforcement learning collect experience from many (N) environments simultaneously using the policy and update it with this cumulative experience. They are broadly divided into two classes: synchronous (Sync) and asynchronous (Aync). Sync contains two synchronization points: first the policy is executed for the entire batch $(o_t \rightarrow a_t)^B_{b=1}$ (A), then actions are executed in all environments, $(s_t, a_t \rightarrow s_{t+1}, o_{t+1})^B_{b=1}$ (B), until $T$ steps have been collected from all $N$ environments. This $(T, N)$-shaped batch of experience is used to update the policy ©. Synchronization reduces throughput as the system spends significant (sometimes the most) time waiting for the slowest environment to finish. This known as is the straggler effect.
Aync removes these synchronization points, thereby mitigating the straggler effect and improving throughput. Actions are taken as soon as they are computed, $a_t \rightarrow o_{t+1}$ (D), the next action is computed as soon as the observation is ready, $o_t \rightarrow a_t$, and the policy is updated as soon as enough experience is collected (E). However, Aync systems are not able to ensure that all experience has been collected by only the current policy and thus must consume near-policy data. This reduces sample efficiency. Thus, status quo leaves us with an unpleasant tradeoff – high sample-efficiency with low throughput or high throughput with low sample-efficiency.
In this work, we propose Variable Experience Rollout (VER). VER combines the strengths of and blurs the line between Sync and Aync. Like Sync, VER collects experience with the current policy and then updates it. Like Aync, VER does not have synchronization points – it computes next actions, steps environments, and updates the policy as soon as possible. The inspiration for VER comes from two key observations:
- Aync mitigates the straggler effect by implicitly collecting a variable amount of experience from each environment – more from fast-to-simulate environments and less from slow ones.
- Both Sync and Aync use a fixed rollout length, $T$ steps of experience. Our key insight is that while a fixed rollout length may simplify an implementation, it is not a requirement for RL.
These two key observations naturally lead us to variable experience rollout (VER), i.e. collecting rollouts with a variable number of steps. VER adjusts the rollout length for each environment based on its simulation speed. It explicitly collects more experience from fast-to-simulate environments and less from slow ones. The result is an RL system that overcomes the straggler effect and maintains sample-efficiency by learning from on-policy data.
VER focuses on efficiently utilizing a single GPU. To enable efficient scaling to multiple GPUs, we combine VER with the decentralized distributed method proposed in DD-PPO.
Benchmarking: Navigation
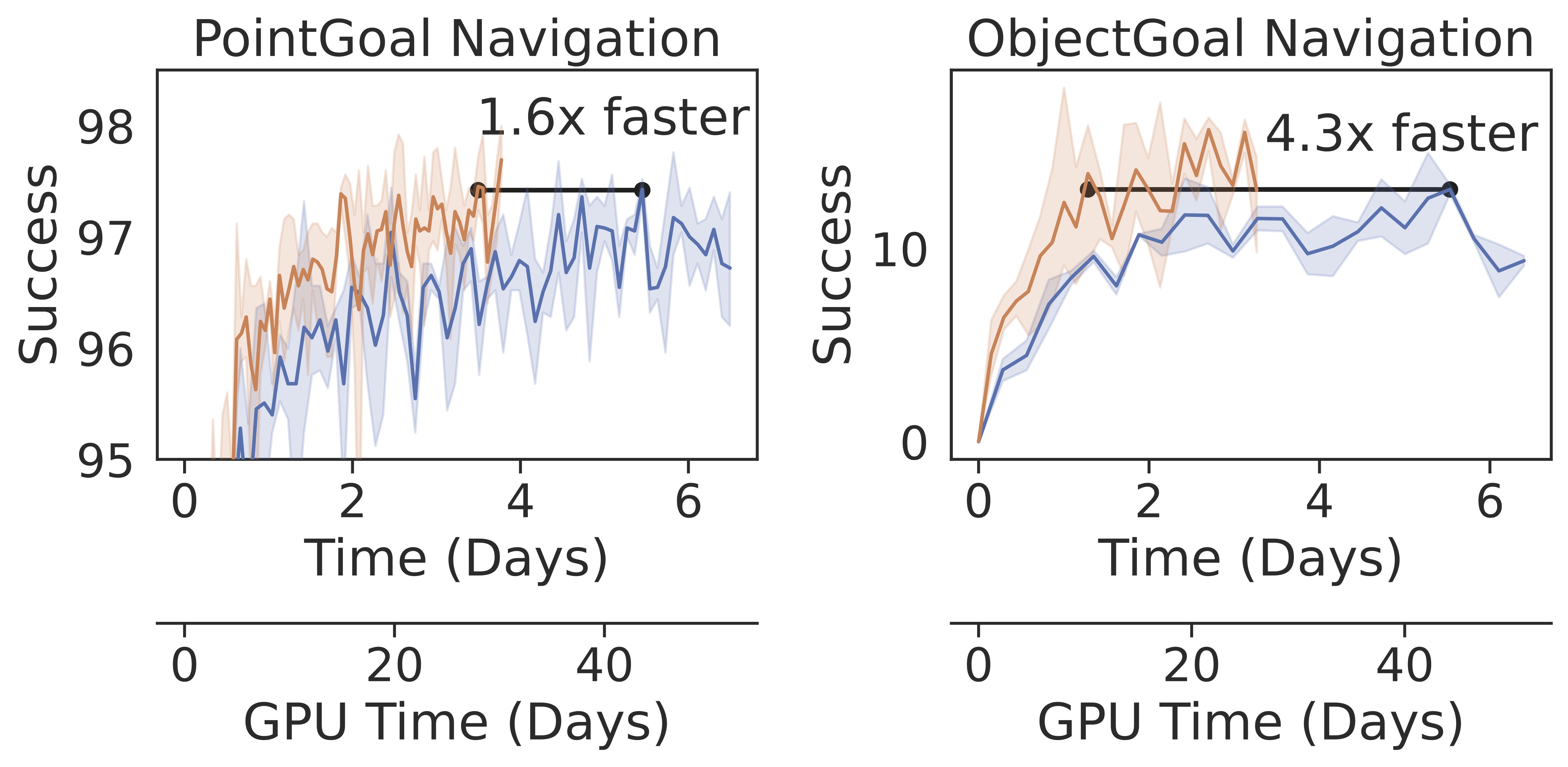
First, we evaluate VER on well-established embodied navigation tasks using Habitat 1.0 on 8 GPUs. VER trains PointGoal navigation 60% faster than DD-PPO, the current state-of-the-art for distributed on-policy RL, with the same sample efficiency. For ObjectGoal navigation, an active area of research, VER uses 340% less compute than DD-PPO with (slightly) better sample efficiency.
Benchmarking: Rearrangement

Next, we evaluate VER on the recently introduced (and significantly more challenging) GeometricGoal rearrangement tasks in Habitat 2.0. In GeoRearrange, a virtual robot is spawned in a new environment and asked to rearrange a set of objects from their initial to desired coordinates. These environments have highly variable simulation time (physics simulation time increases if the robot bumps into something) and require GPU-acceleration (for photo-realistic rendering), limiting the number of environments that can be run in parallel.
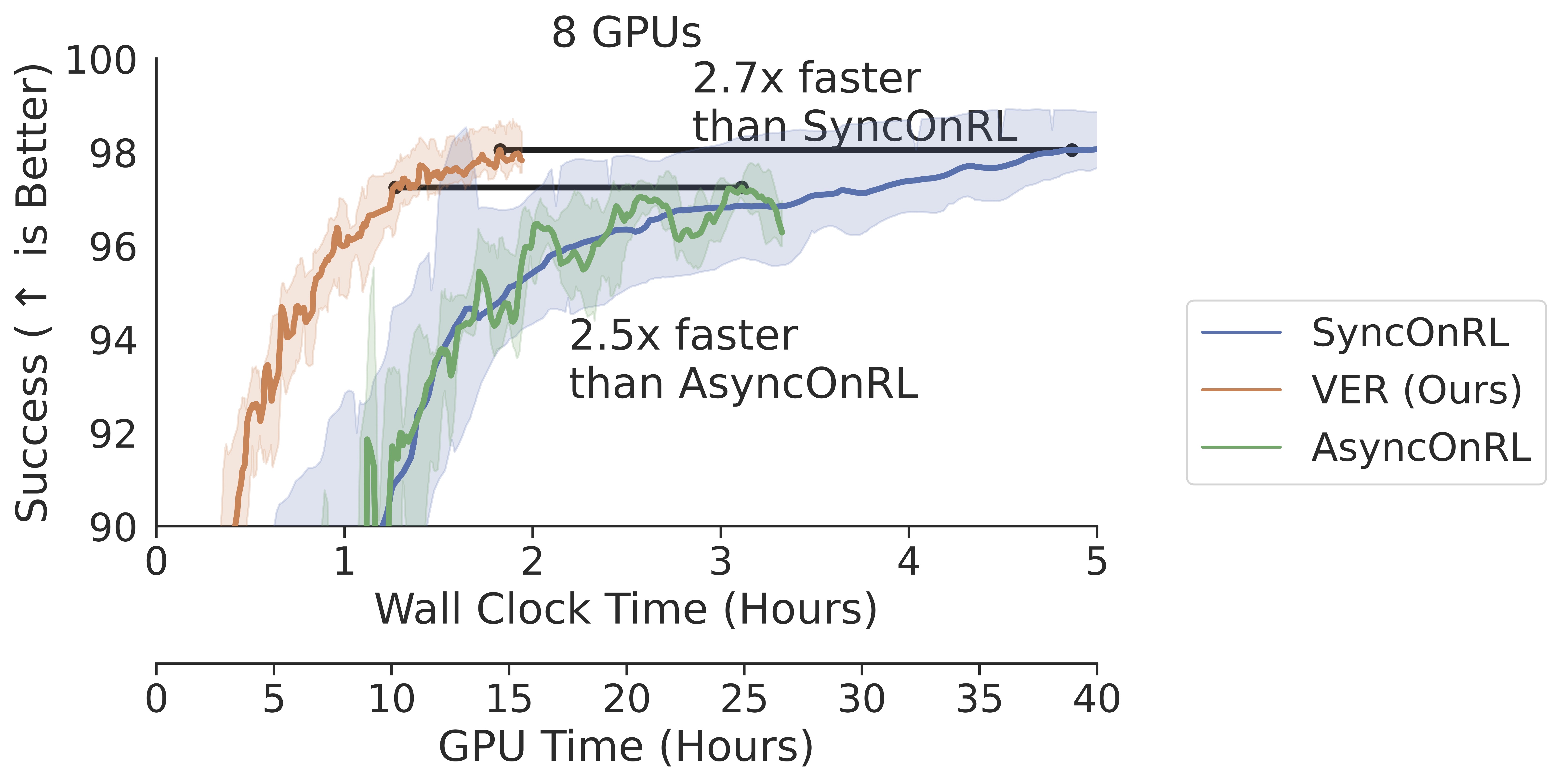
On 1 GPU, VER is 150% faster (2.5x speedup) than DD-PPO with the same sample efficiency. VER is as fast as SampleFactory, the state-of-the-art Async, with the same sample efficiency. VER is as fast as Aysnc in pure throughput; this is a surprisingly strong result. Async never stops collecting experience and should, in theory, be a strict upper bound on performance. VER is able to match Async for environments that heavily utilize the GPU for rendering, like Habitat. In Async, learning, inference, and rendering contend the GPU which reduces throughput. In VER, inference and rendering contend for the GPU while learning does not.
On 8 GPUs, VER achieves better scaling than DD-PPO, achieving a 6.7x speed-up (vs.~6x for DD-PPO) due to lower variance in experience collection time between GPU-workers. Due to this efficient multi-GPU scaling, VER is 70% faster (1.7x speedup) than SampleFactory on 8 GPUs and has better sample efficiency as it learns from on-policy data.
Embodied Rearrangement: Emergence of Navigation
Finally, we leverage these SysML contributions to study open research questions posed in prior work. Specifically, we train RL policies for mobile manipulation skills (Navigate, Pick, Place, etc) and chain them via a task planner. Prior work (Szot et al, 2021) called this approach TP-SRL and identified a critical “handoff problem” – downstream skills are set up for failure by small errors made by upstream skills (e.g. the Pick skill failing because the navigation skill stopped the robot a bit too far from the object ).
We demonstrate a number of surprising findings when TP-SRL is scaled via VER. Most importantly, we find the emergence of navigation when skills that do not ostensibly require navigation (Pick) are trained with navigation actions enabled. In principle, Pick and Place policies do not need to navigate during training since the objects are always in arm’s reach, but in practice they learn to navigate to recover from their mistakes and this results in strong out-of-distribution test-time generalization. Specifically, TP-SRL without a navigation skill achieves 50% success on NavPick and 20% success on a NavPickNavPlace task simply because the Pick and Pace skills have learned to navigate (sometimes across the room!). TP-SRL with a Navigate skill performs even stronger: 90% on NavPickNavPlace and 32% on 5 successive NavPickNavPlaces (called Tidy House), which are +32% and +30% absolute improvements over Szot et al 2021, respectively. Prepare Groceries and Set Table, which both require interaction with articulated receptacles (fridge, drawer), remain as open problems (5% and 0% Success, respectively) and are the next frontiers.
If you’ve found this interesting, you can read the full paper here. Above is the introduction (albeit slightly modified), so are many interesting details that weren’t covered.
Example of TP-SRL without a navigation skill
Examples of Pick/Place during training
Pick
Place
Notice how much closer the policies are initialized during training than in the video of TP-SRL without a navigation skill.